Browserify makes your frontend javascript more modularized and it helps to organize the frontend codes
much better. But only use browserify is not enough if you are using some legacy libs. Which means such
libs are not qualified for npm publication. for example some libs just simply use a global variable: window.Module
Introduce to browserify-shim:
For those libs which expose themselves as window.Module, add the following to your package.json:
It’s a Nodejs project, which means that you need to run npm
You use gulp or grunt or whatever building tools
Your app is running under Apache2, it means the default user www-data of Apache don’t have permission to run some command.
You want:
Every time there is push, deploy it to your VPS and run building scripts.
Steps:
Make sure owner of /var/www/ is www-data (default Apache user). If not
1
sudo chown -R www-data:www-data /var/www/
Do ssh authentication for git, so that it won’t ask for user&pass
1 2 3 4 5 6 7 8 9 10
sudo -Hu www-data mkdir /var/www/.ssh sudo -Hu www-data ssh-keygen -t rsa -C "your@email.com"# use your github email sudo -Hu www-data cat /var/www/.ssh/id_rsa.pub #copy it open https://github.com/settings/ssh #paste the ssh key here # clone the repo use ssh url: git clone git@github.com:<user>/<repo>.git
# type *ssh -T git@github.com* if you see something like: Hi username! You've successfully authenticated, but GitHub does not provide shell access. # you are now authenticated!
Think about that you made an awesome React component, you don’t just want to use it in your own project but also want to publish
to npm to share with others. However, awesome ui can not live without css. So you either use a bunch of inline css, or write in
the README to tell people who use this component to also include an external css file. This is really not a good idea to write
isolate React Component.
Here we introduce CSS Modules. The idea is that you can import a css file as it is
a normal npm module. In the we will use react-css-modules
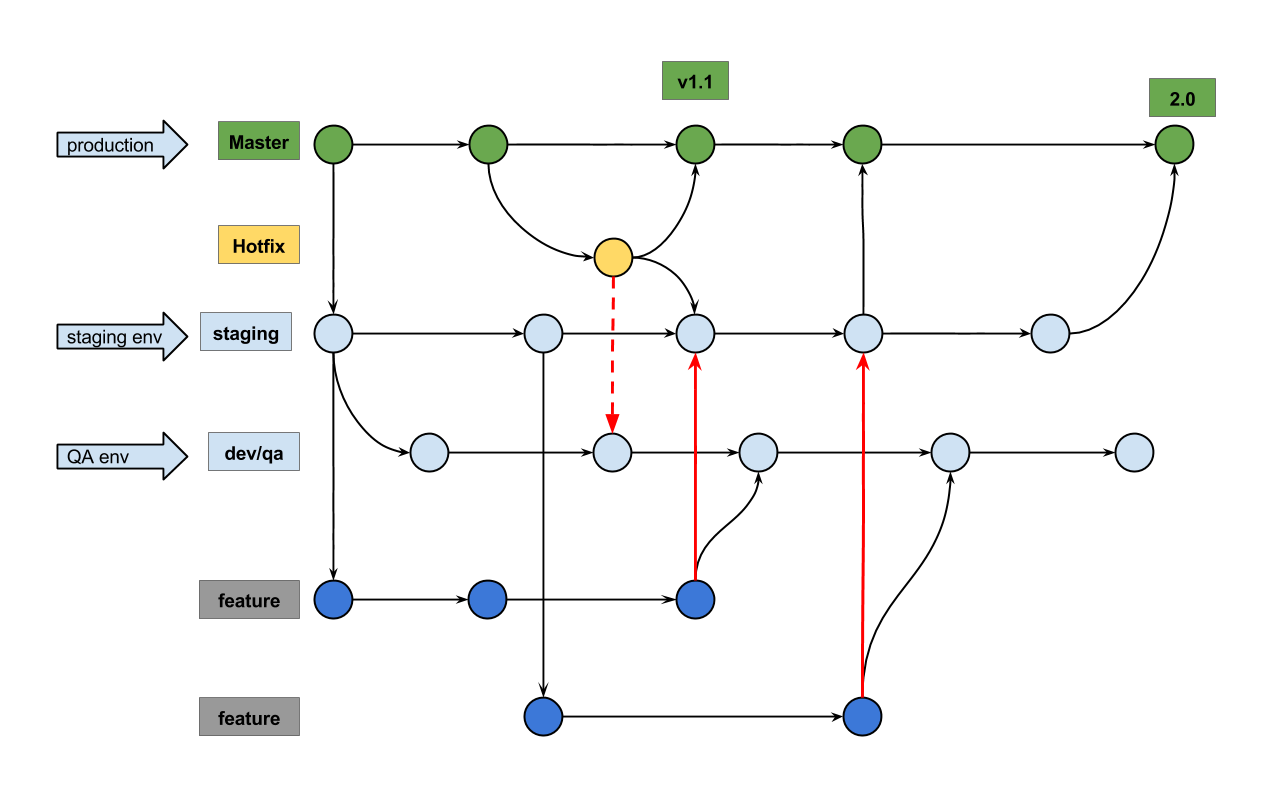
They fit for different size of project and team. Gitflow is widely use in the larger team and it handles a more complicated scenario. It basically has two branches, master is the production branch,
and develop is the branch which all the feature branches be merged to. When new features are enough for next release or it’s getting to the next release date, creating a release branch from develop. From now
on, no new features should be merged to release except bugfixes. A hotfix branch should be created from master, and be mergerd back to master and develop.
But for the team which has the requirements that not all the features need to go to production in the next release. It is a little difficult to handle this case because all the commits from feature branch are merged
into develop. This is a real world scenario for those team who has QA environment. Because all the features should be in this branch and be well tested in this environment.
Cherry-pick from develop to master may work but it’s not decent enough and you need to do it carefully in order not to forget some commits. So here comes out a Variant version of gitflow which takes selective merge
into consideration.
A new branch staging is created from master. This branch should never be touched until the next release. In another word, master and staging should be always the same.
Feature branches should be created from staging.
dev/qa branch should be initially created from staging.
When feature is done, merge it to dev/qa for QA testing.
For features which are going to involved in the next release, send pull request from feature to staging and the reviewer should review and merge it.
Always create hotfix branch from master and merge it back when bug resolved. Also remember to merge it to staging and do cherry-pick from dev/qa so that the fixes are applied to both environment. If needed, send pull request from hotfix to master and staging.
When staging is ready for production, merge it to master and give it a tag.
Notice
Merging feature branches from dev/qa and resoving the conflicts there. DO NOT do this at feature branch.
Remember the hotfix and apply it to both staging and dev/qa.
Alway send pull request from feature to staging, so that the reviewers can review and merge it.
It is a common issue that your page get messed up with non-English characters, for example Chinese and some European characters are displayed as ‘??? ???? ?????’ or ‘���� ����’.
Sometimes it’s even worse if you need to communicate with another system that has different character encoding from yours. for example: GBK(GB18030) and UTF-8
What is Character Encoding and Character Set?
Some concepts we need to make clear before we continue. People usually dont have a clear distinction between Character Encoding and Character Sets.
Someone may even ask what’s the difference between UTF-8 and Unicode.
Unicode is a Character Set, just as the name says, it’s a set of characters which mapped to a set of unique numbers(code point). for example in the Unicode world,
A is 41, an 1 is 31 and 💩 is 1F4A9
1
A --- U+0041
1 --- U+0031
💩 --- U+1F4A9
While Character Encoding is a set of mappings between the numbers of Character Sets and the bytes in computer. for example in UTF-8:
The characters are translated to binary and can be stored in disk or memory now. It’s not that hard, right?
What are those Mysterious ??? and � ?
We know that data are transfered as binary in the wire, so when a browser get the binary data, it have to know what Character Encoding the data was used
so that it can represent the right Character as expected.
So, in a browser you must tell the Character Encoding otherwise the browser will guess or it will use the default Character Encoding and that’s horrible…
Tell a browser what Character Encoding you are using
1.Specify Encoding in the http response header
1
Content-Type:text/html; charset=UTF-8
In php you can do this by setting the following in php.ini
1
default_charset = "UTF-8"
or if you are using Apache server, in httpd.conf and add:
1
AddDefaultCharset utf-8
But this is not a good way, think about that if you have a webserver that serves couple of websites with different Encoding(bad idea..)
So a better way could:
2.Use HTML meta tag
1 2 3 4 5
<!--HTML 4, which default is ISO-8859-1--> <metahttp-equiv="Content-Type"content="text/html; charset=utf-8">
<!--HTML 5, default is UTF-8--> <metacharset="utf-8">
Make sure that your data are well encoded
You have told the browser what Encoding you are using. What if you are using mixed Encoding in your server side? That could be happened.
for example you have page a.php which file encoding is utf-8 but it read some content from a file which is another file encoding,
for example GB18030(GBK)
you will see part of the page is correct but the input value maybe incorrect. Now when you submit the form, the server will never get the right value.
And think about reading a database with different encoding? That’s terrible right?
There are thousands of articles that suggest to use UTF-8 and Unicode, so please do that to make yours and others life easy.
Everything works fine after migrating my blog to hexo, it’s just not cool that everytime I have to run hexo deploy to publish my posts.
Cool boy uses Travis-CI, right?
Step 1 - generate a personal access token at Github
Regular Expression is widely used in the programmig world but it may not been used so frequently in someone’s daily work. Like me, sometime i forgot
the syntax of Regular Expression or just not able to recall the relevant Javascript functions. Then i will need to search the Regular Expression manual and
read Javascript references. This post will cover some of the commonly used functions of Regular Expression in Javascript.
Creating a Regular Expression
There are two ways to create a Regular Expression in Javascript: a literal notation and a RegExp constructor, for example:
1 2
var regex = /^ab+c$/ig; // literal notation: /pattern/flags var regex = newRegExp('^ab+c$', 'ig'); // RegExp constructor: new RegExp(pattern[, flags])
Pattern string
When use literal notation, pattern is surrounded with two slash /pattern/ while in RegExp constructor it’s a normal string, but notice that when using
constructor way the pattern string should be escaped. for example:
1 2
var regex = /\d+/; var regex = newRegExp('\\d+'); // double back slash are used
Flags
A flag can be any of the combination of the following values:
1 2 3
i //ignore cases g //global match m //multiline; treat beginning and end characters (^ and $) as working over multiple lines
If you simply want to find whether a pattern is found in a string, test() method would be a good choice. It returns true or false.
For example: test if a string has a pattern
1 2
var regex = /^ab+c/; regex.test('abcdef'); //true
What if you want to find out how many times a pattern appears in a tring?
Another important property you should know about RegExp object: RegExp.lastIndex.
1 2 3 4 5 6 7 8 9 10
// find out how many times a number group appears in a string var regex = /\d+/g; // with g flag! var str = 'aa23bb22cc1dd'; var num = 0; while (regex.test(str) !== false) { var msg = 'Next match starts at ' + regex.lastIndex; num++; console.log(msg); } console.log('There are ' + num + ' groups of number in this string'); // num = 3
You can find that value of lastIndex updated when everytime run test() method.
But! NOTICE!! lastIndex updated ONLY IF you have ‘g’ flag in your Regular Expression.
2.RegExp.prototype.exec()
The exec() method take a string and execute the a search on this string. It return an Array or null.
If you understand the return Array, then you understand most of Javascript RegExp :)
Let see an example in detail.
Say you want to find out the country code, area code and phone number of a full phone number string. for example: +86-028-84553673
let’s do an stupid simple test ;)
1 2 3 4 5 6 7 8 9 10
var regex = /\+(\d{2})-(\d{3})-(\d{8})/g; var phoneNum = 'Tom: +86-028-84553673, Juha: +86-010-23457788'; var result; while ((result = regex.exec(phoneNum)) !== null) { var msg = 'Found ' + result[0]; msg += '\nCountry Code: ' + result[1]; msg += '\nArea code: ' + result[2]; msg += '\nNumber: ' + result[3]; console.log(msg); }
Output:
1 2 3 4 5 6 7 8
Found +86-028-84553673 Country Code: 86 Area code: 028 Number: 84553673 Found +86-010-23457788 Country Code: 86 Area code: 010 Number: 23457788
Let’s take a look at the result object:
1 2
result[0] : the full string that matched the pattern result[1]...[n] : the pattern that you are willing to preserve which you placed in Parentheses ()
CORS stands for Cross Origin Resouce Sharing. It means that requests for resources from another domain than the domain where the requests are making.
For security reasons, some HTTP requests are restricted by same origin policy. For example an Ajax request, we can not make ajax request from domainA.com to request resource from domainB.com. But this could be painful if you are making a restful API which you host your API in another domain like: api.mydeomain.com.
When it is used?
As described in MDN:
1
Invocations of the XMLHttpRequest API in a cross-site manner, as discussed above.
Web Fonts (for cross-domain font usage in @font-face within CSS)
WebGL textures.
Images drawn to a canvas using drawImage.
How it work?
Here we talk about two kinds of cross-site request. They are simple requests and preflight request.
Simple request behaviour:
1
Client: Hey man, can I take/put some apples from/to your storage?
Server: No. --end
Preflight request behabiour:
1
Client: Hey man, can I take/put something from/to your storage?
Server: Yes please. (or No --end)
Client: Cool! Please give me some apples.
A simple cross-site request is one that(MDN):
1
Only uses GET, HEAD or POST. If POST is used to send data to the server, the Content-Type of the data sent to the server with the HTTP POST request is one of application/x-www-form-urlencoded, multipart/form-data, or text/plain.
Does not set custom headers with the HTTP Request (such as X-Modified, etc.)
Otherwise, it is a Preflight request. But, how a simple request actually looks like?
Take a simple GET request for example, if you open chrome dev tool and you will find something like this from http request headers:
1
GET /account/user/ HTTP/1.1
...
...
Origin: http://client.localhost
It tells the server: I am from http://client.localhost and I want to get user infomation(/account/user/).
It tells the client: we allow anyone(as you can see:Access-Control-Allow-Origin: *) came to take user data from here and here is the data. If there is no Access-Control-Allow-Origin provided in response header, the browser will give you an error.
Preflight request is a little different. Client actually will have two requests. The first request is send with ‘OPTIONS’ method. If success, then make the actuall request. Take a POST request for an example:
First it makes a OPTIONS request:
1
OPTIONS /save/user/ HTTP/1.1
...
...
Origin: http://client.localhost
Access-Control-Request-Method: POST
It ‘test’ the server to see if it allows the origin domain and request method for the specific route.
Then the server response:
1
HTTP/1.1 200 OK
...
...
Access-Control-Allow-Origin: http://client.localhost
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Max-Age:3600
Server says OK, you are allowed and can use POST,GET,OPTIONS methods
Finally make the actuall POST request:
1
POST /save/user/ HTTP/1.1
...
...
Content-Type:application/json;charset=UTF-8
Origin:http://client.localhost
If you need to apply patches from a new release of an open source software that used in your project. However, you lost all the git history of the original repo(for example download release.tar.gz directly) or you just want to apply some of those Fixed commits. Then git format-patch probably a good choice.
This command means that creating patch from commit ‘55befce’ to ‘1b30d93’. And –binary will output a binary diff that you can use to apply the changes to binary file. Actually, –binary is enabled by default. But the difference is that if you create patch files with –binary, all the patch files will use full index instead of the first handful of characters.
this is the difference when outputting patch files.
1 2
index 5150093..ebbca95 100644 index 51500932980c91ef1e6a656ce01dafbca089d148..ebbca9519e7c742eca5bb58f244e704605155474 100644
while if there is no –binary, for those not binary files will use the short one and binary files will use the longer one. So, i guess that’s really doesn’t matter whether use –binary or not.
But if you dont want to output the diff of binary files, use –no-binary instead.
Applying the patch
Now you have a list of *.patch files. Run the following command to apply it.
1
git am -3 path/to/*.patch
-3 means that when git trys to apply this patch, it’ll do a 3-way merge. If there is no conflict, a new commit will be auto commited. if there is conflict, resolve the conflicts then:
1
git am --continue
If error happened and git can not auto merge the files, you will need to apply the patch manully. Open the patch files and find what has changed, then just do it manully.. Abort the current process first:
1
git am --abort
when you’ve done it manully, then commit it as normal.
var concat = require('gulp-concat'); var uglify = require('gulp-uglify'); var sourcemaps = require('gulp-sourcemaps');
var paths = { scripts: 'src/**/*.js' };
gulp.task('scripts', function() { // Minify and copy all JavaScript (except vendor scripts) // with sourcemaps all the way down return gulp.src(paths.scripts) .pipe(sourcemaps.init()) .pipe(concat('all.js')) .pipe(uglify()) .pipe(sourcemaps.write()) .pipe(gulp.dest('build/js')); });
// Rerun the task when a file changes gulp.task('watch', function() { gulp.watch(paths.scripts, ['scripts']); });
// The default task (called when you run `gulp` from cli) gulp.task('default', ['watch', 'scripts']);